
我们学院的一位教授之前去美国开会,入境的时候海关官员就问他:既然你会计算机,那你说说你用的都是什么语言吧?
教授随口就答了个 Java。海关一看是懂行的,也就放行了,边敲章还边说他们上学那会学的是 C+。我还特意去查了下,真有叫 C+ 的语言,但是这里海关官员应该指的是 C++。
事后教授告诉我们,他当时差点就问海关,是否知道 Java 和 C++ 在运行方式上的区别。但是又担心海关官员拿他的问题来考别人,也就没问出口。那么,下次你去美国,不幸地被海关官员问这个问题,你懂得如何回答吗?
作为一名 Java 程序员,你应该知道,Java 代码有很多种不同的运行方式。比如说可以在开发工具中运行,可以双击执行 jar 文件运行,也可以在命令行中运行,甚至可以在网页中运行。当然,这些执行方式都离不开 JRE,也就是 Java 运行时环境。
实际上,JRE 仅包含运行 Java 程序的必需组件,包括 Java 虚拟机以及 Java 核心类库等。我们 Java 程序员经常接触到的 JDK(Java 开发工具包)同样包含了 JRE,并且还附带了一系列开发、诊断工具。
然而,运行 C++ 代码则无需额外的运行时。我们往往把这些代码直接编译成 CPU 所能理解的代码格式,也就是机器码。
比如下图的中间列,就是用 C 语言写的 Helloworld 程序的编译结果。可以看到,C 程序编译而成的机器码就是一个个的字节,它们是给机器读的。那么为了让开发人员也能够理解,我们可以用反汇编器将其转换成汇编代码(如下图的最右列所示)。
既然 C++ 的运行方式如此成熟,那么你有没有想过,为什么 Java 要在虚拟机中运行呢,Java 虚拟机具体又是怎样运行 Java 代码的呢,它的运行效率又如何呢?
今天我便从这几个问题入手,和你探讨一下,Java 执行系统的主流实现以及设计决策。
为什么 Java 要在虚拟机里运行?
Java 作为一门高级程序语言,它的语法非常复杂,抽象程度也很高。因此,直接在硬件上运行这种复杂的程序并不现实。所以呢,在运行 Java 程序之前,我们需要对其进行一番转换。
这个转换具体是怎么操作的呢?当前的主流思路是这样子的,设计一个面向 Java 语言特性的虚拟机,并通过编译器将 Java 程序转换成该虚拟机所能识别的指令序列,也称 Java 字节码。这里顺便说一句,之所以这么取名,是因为 Java 字节码指令的操作码(opcode)被固定为一个字节。
举例来说,下图的中间列,正是用 Java 写的 Helloworld 程序编译而成的字节码。可以看到,它与 C 版本的编译结果一样,都是由一个个字节组成的。
并且,我们同样可以将其反汇编为人类可读的代码格式(如下图的最右列所示)。不同的是,Java 版本的编译结果相对精简一些。这是因为 Java 虚拟机相对于物理机而言,抽象程度更高。
Java 虚拟机可以由硬件实现 [1],但更为常见的是在各个现有平台(如 Windows_x64、Linux_aarch64)上提供软件实现。这么做的意义在于,一旦一个程序被转换成 Java 字节码,那么它便可以在不同平台上的虚拟机实现里运行。这也就是我们经常说的“一次编写,到处运行”。
虚拟机的另外一个好处是它带来了一个托管环境(Managed Runtime)。这个托管环境能够代替我们处理一些代码中冗长而且容易出错的部分。其中最广为人知的当属自动内存管理与垃圾回收,这部分内容甚至催生了一波垃圾回收调优的业务。
除此之外,托管环境还提供了诸如数组越界、动态类型、安全权限等等的动态检测,使我们免于书写这些无关业务逻辑的代码。
Java 虚拟机具体是怎样运行 Java 字节码的?
下面我将以标准 JDK 中的 HotSpot 虚拟机为例,从虚拟机以及底层硬件两个角度,给你讲一讲 Java 虚拟机具体是怎么运行 Java 字节码的。
从虚拟机视角来看,执行 Java 代码首先需要将它编译而成的 class 文件加载到 Java 虚拟机中。加载后的 Java 类会被存放于方法区(Method Area)中。实际运行时,虚拟机会执行方法区内的代码。
如果你熟悉 X86 的话,你会发现这和段式内存管理中的代码段类似。而且,Java 虚拟机同样也在内存中划分出堆和栈来存储运行时数据。
不同的是,Java 虚拟机会将栈细分为面向 Java 方法的 Java 方法栈,面向本地方法(用 C++ 写的 native 方法)的本地方法栈,以及存放各个线程执行位置的 PC 寄存器。
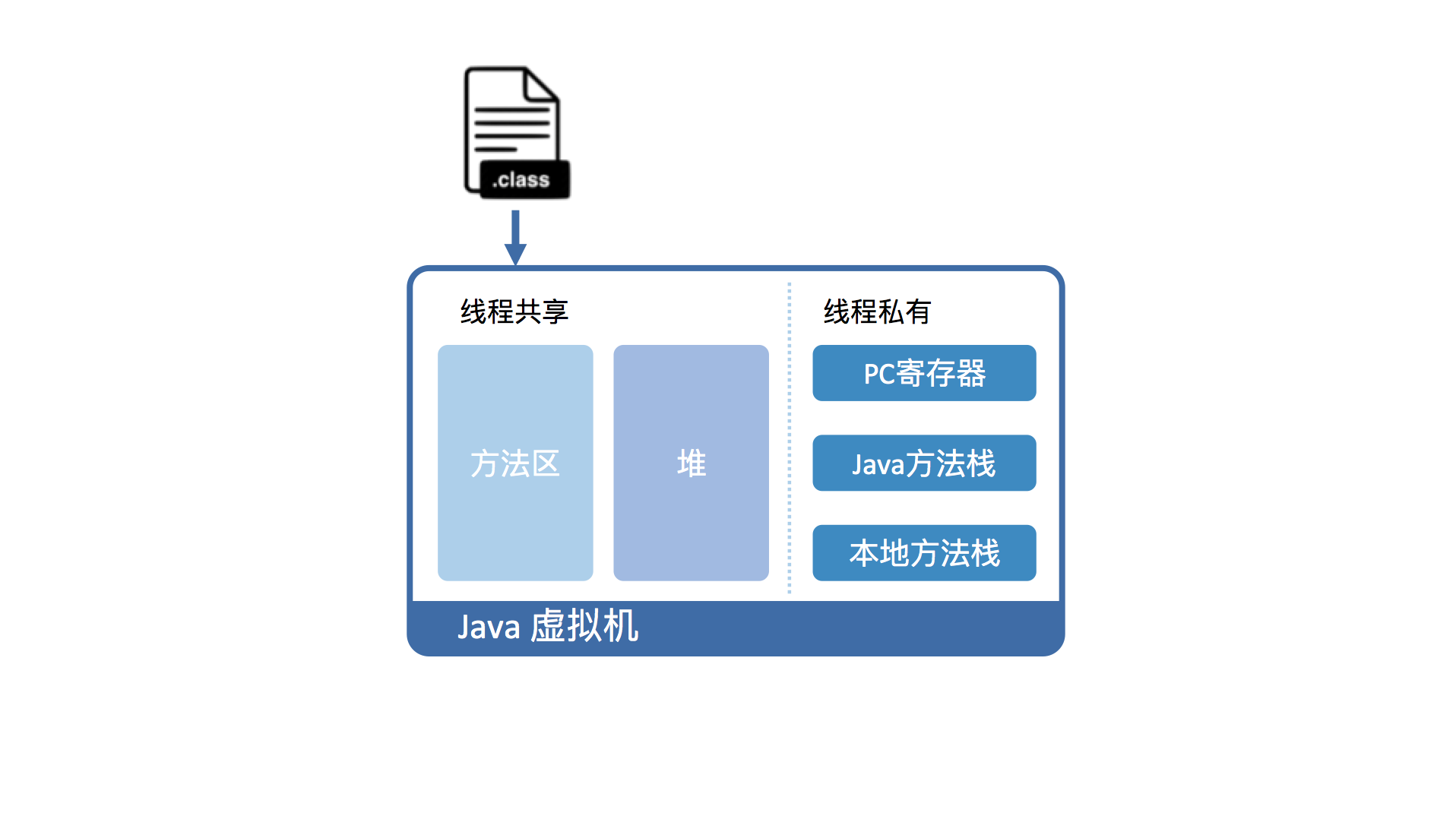
在运行过程中,每当调用进入一个 Java 方法,Java 虚拟机会在当前线程的 Java 方法栈中生成一个栈帧,用以存放局部变量以及字节码的操作数。这个栈帧的大小是提前计算好的,而且 Java 虚拟机不要求栈帧在内存空间里连续分布。
当退出当前执行的方法时,不管是正常返回还是异常返回,Java 虚拟机均会弹出当前线程的当前栈帧,并将之舍弃。
从硬件视角来看,Java 字节码无法直接执行。因此,Java 虚拟机需要将字节码翻译成机器码。
在 HotSpot 里面,上述翻译过程有两种形式:第一种是解释执行,即逐条将字节码翻译成机器码并执行;第二种是即时编译(Just-In-Time compilation,JIT),即将一个方法中包含的所有字节码编译成机器码后再执行。
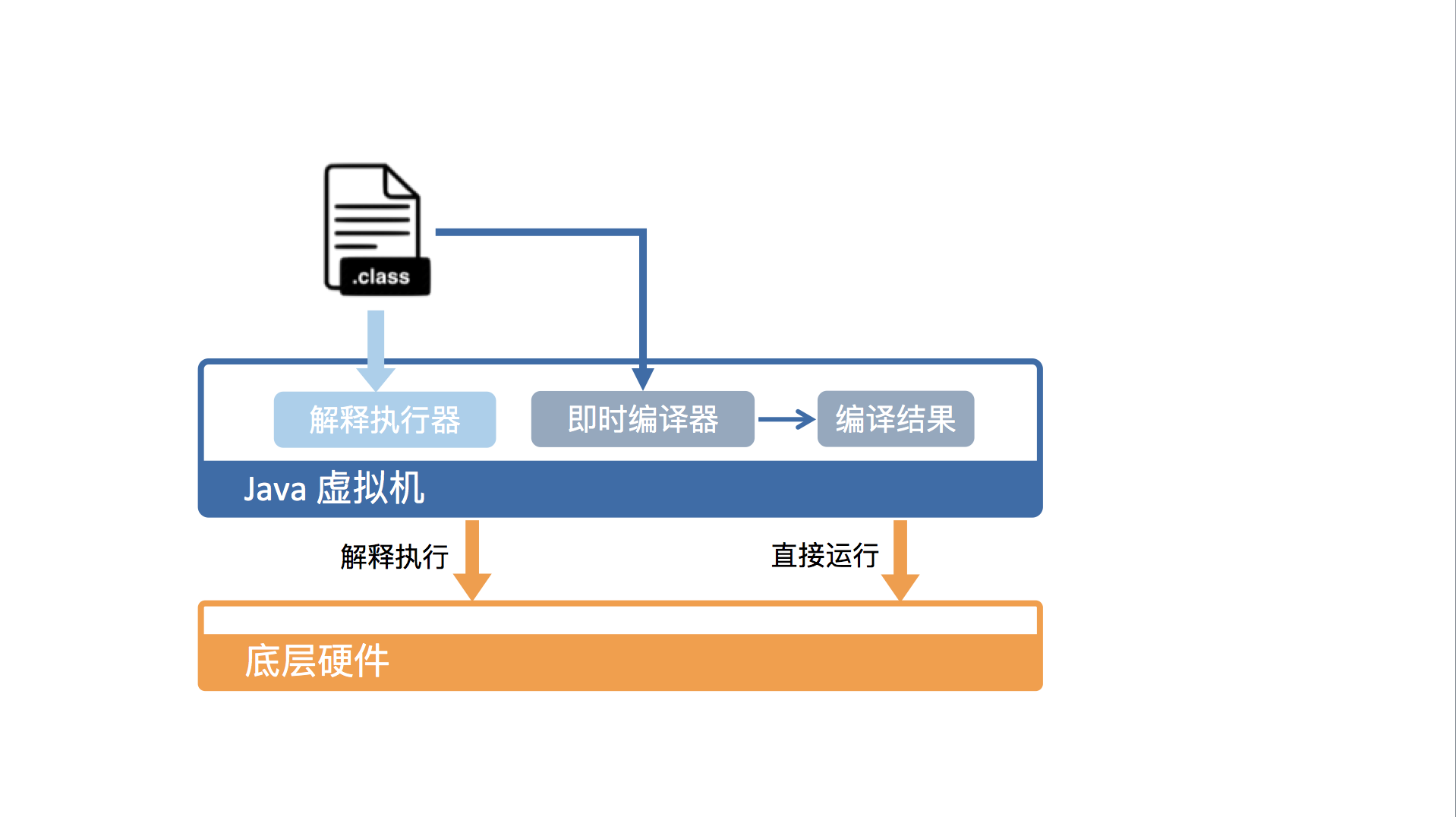
前者的优势在于无需等待编译,而后者的优势在于实际运行速度更快。HotSpot 默认采用混合模式,综合了解释执行和即时编译两者的优点。它会先解释执行字节码,而后将其中反复执行的热点代码,以方法为单位进行即时编译。
Java 虚拟机的运行效率究竟是怎么样的?
HotSpot 采用了多种技术来提升启动性能以及峰值性能,刚刚提到的即时编译便是其中最重要的技术之一。
即时编译建立在程序符合二八定律的假设上,也就是百分之二十的代码占据了百分之八十的计算资源。
对于占据大部分的不常用的代码,我们无需耗费时间将其编译成机器码,而是采取解释执行的方式运行;另一方面,对于仅占据小部分的热点代码,我们则可以将其编译成机器码,以达到理想的运行速度。
理论上讲,即时编译后的 Java 程序的执行效率,是可能超过 C++ 程序的。这是因为与静态编译相比,即时编译拥有程序的运行时信息,并且能够根据这个信息做出相应的优化。
举个例子,我们知道虚方法是用来实现面向对象语言多态性的。对于一个虚方法调用,尽管它有很多个目标方法,但在实际运行过程中它可能只调用其中的一个。
这个信息便可以被即时编译器所利用,来规避虚方法调用的开销,从而达到比静态编译的 C++ 程序更高的性能。
为了满足不同用户场景的需要,HotSpot 内置了多个即时编译器:C1、C2 和 Graal。Graal 是 Java 10 正式引入的实验性即时编译器,在专栏的第四部分我会详细介绍,这里暂不做讨论。
之所以引入多个即时编译器,是为了在编译时间和生成代码的执行效率之间进行取舍。C1 又叫做 Client 编译器,面向的是对启动性能有要求的客户端 GUI 程序,采用的优化手段相对简单,因此编译时间较短。
C2 又叫做 Server 编译器,面向的是对峰值性能有要求的服务器端程序,采用的优化手段相对复杂,因此编译时间较长,但同时生成代码的执行效率较高。
从 Java 7 开始,HotSpot 默认采用分层编译的方式:热点方法首先会被 C1 编译,而后热点方法中的热点会进一步被 C2 编译。
为了不干扰应用的正常运行,HotSpot 的即时编译是放在额外的编译线程中进行的。HotSpot 会根据 CPU 的数量设置编译线程的数目,并且按 1:2 的比例配置给 C1 及 C2 编译器。
在计算资源充足的情况下,字节码的解释执行和即时编译可同时进行。编译完成后的机器码会在下次调用该方法时启用,以替换原本的解释执行。
总结与实践
今天我简单介绍了 Java 代码为何在虚拟机中运行,以及如何在虚拟机中运行。
之所以要在虚拟机中运行,是因为它提供了可移植性。一旦 Java 代码被编译为 Java 字节码,便可以在不同平台上的 Java 虚拟机实现上运行。此外,虚拟机还提供了一个代码托管的环境,代替我们处理部分冗长而且容易出错的事务,例如内存管理。
Java 虚拟机将运行时内存区域划分为五个部分,分别为方法区、堆、PC 寄存器、Java 方法栈和本地方法栈。Java 程序编译而成的 class 文件,需要先加载至方法区中,方能在 Java 虚拟机中运行。
为了提高运行效率,标准 JDK 中的 HotSpot 虚拟机采用的是一种混合执行的策略。
它会解释执行 Java 字节码,然后会将其中反复执行的热点代码,以方法为单位进行即时编译,翻译成机器码后直接运行在底层硬件之上。
HotSpot 装载了多个不同的即时编译器,以便在编译时间和生成代码的执行效率之间做取舍。
下面我给你留一个小作业,通过观察两个条件判断语句的运行结果,来思考 Java 语言和 Java 虚拟机看待 boolean 类型的方式是否不同。
下载 asmtools.jar [2] ,并在命令行中运行下述指令(不包含提示符 $):
[1] : https://en.wikipedia.org/wiki/Java_processor
[2]: https://wiki.openjdk.java.net/display/CodeTools/asmtools

版权归极客邦科技所有,未经许可不得转载
精选留言
请教老师一个问题,网上我没有搜到。
服务器线程数爆满,使用jstack打印线程堆栈信息,想知道是哪类线程数太多,但是堆栈里全是一样的信息且没有任何关键信息,是哪个方法创建的,以及哪个线程池的都看不到。
如何更改打印线程堆栈信息的代码(动态)让其打印线程池信息呢?
https://blog.csdn.net/jiaobuchong/article/details/83037467
flag = iconst_1 = true
awk把stackframe中的flag改为iconst_2
if(flag)比较时ifeq指令做是否为零判断,常数2仍为true,打印输出
if(true == flag)比较时if_cmpne做整数比较,iconst_1是否等于flag,比较失败,不再打印输出
asmtools下载地址:
https://adopt-openjdk.ci.cloudbees.com/view/OpenJDK/job/asmtools/lastSuccessfulBuild/artifact/asmtools-6.0.tar.gz;
先是在window环境里,awk不能使用,看https://zh.wikipedia.org/wiki/Awk,AWK是一种优良的文本处理工具,Linux及Unix环境中现有的功能最强大的数据处理引擎之一,于是转战Linux,
[root@localhost cqq]# javac Foo.java
[root@localhost cqq]# java Foo
Hello,Java
Hello,JVM
[root@localhost cqq]# java -cp /cqq/asmtools.jar org.openjdk.asmtools.jdis.Main Foo.class>Foo.jasm.1
[root@localhost cqq]# ls
asmtools.jar Foo.class Foo.jasm.1 Foo.java
[root@localhost cqq]# vi Foo.jasm.1
[root@localhost cqq]# awk 'NR==1,/iconst_1/{sub(/iconst_1/,"iconst_2")} 1' Foo.jasm.1>Foo.jasm
[root@localhost cqq]# java -cp /cqq/asmtools.jar org.openjdk.asmtools.jasm.Main Foo.jasm
[root@localhost cqq]# java Foo
Hello,Java
结果为啥是这个看点赞第一的高手;
另外asmtools使用方式还可以这样子:
java -jar asmtools.jar jdis Foo.class>Foo.jasm.1
java -jar asmtools.jar jasm Foo.jasm
1-1:可以轻松实现Java代码的跨平台执行
1-2:JVM提供了一个托管平台,提供内存管理、垃圾回收、编译时动态校验等功能
1-3:使用JVM能够让我们的编程工作更轻松、高效节省公司成本,提示社会化的整体快发效率,我们只关注和业务相关的程序逻辑的编写,其他业务无关但对于编程同样重要的事情交给JVM来处理
2:听完此节的课程的疑惑(之前就没太明白,原期待听完后不再疑惑的)
2-1:Java源代码怎么就经过编译变成了Java字节码?
2-2:JVM怎么就把Java字节码加载进JVM内了?先加载那个类的字节码?它怎么定位的?拿到后怎么解析的?不会整个文件放到一个地方吧?使用的时候又是怎么找到的呢?这些感觉还是黑盒
2-3:JVM将内存区域分成堆和栈,然后又将栈分成pc寄存器、本地方法栈、Java方法栈,有些内存空间是线程可共享的,有些是线程私有的。现在也了解不同的内存区块有不同的用处,不过他们是怎么被划分的哪?为什么是他们,不能再多几种或少几种了吗?共享的内存区和私有的又是怎么控制的哪?
我觉得理由不充分,JAVA为什么不能像c++一样直接转成机器码呢?从理论上是可以用编译器来实现这个的功能的。问题在于直接像c++那样编译成机器码,就实现不了跨平台了。那么是不是跨平台才是引入JAVA虚拟机的重要原因呢 。请老师解答
1、NR==1,/iconst_1/ 是用于匹配行 匹配第一行到第一个出现iconst_1的行
2、{}进行脚本执行。针对第一步中匹配的行执行内置的字符串函数sub 做替换
3、1 都会被执行。在awk 1被计算为true,表现为默认操作 print $0 也就是打印整行
整体效果是打印所以文本行,但第一个出现iconst_1的做替换。
我们导师当时是这么解释的,c是所有CPU指令集的交集,而jit可以根据当前的CPU进行优化,调用交集之外的CPU指令集,往往这部分指令集效率很高。
作者如何看待这句话?
Java虚拟机规范中,boolean类型要转换为int类型,true => 1,false => 0;
在编译而成的class文件中,除了字段和传入参数外,基本看不出boolean类型:
比如,第一次时为:
public class Foo {
public Foo() {
}
public static void main(String[] var0) {
byte flag = 1;
if (flag != 0) {
System.out.println("Hello, Java!");
}
if (flag == 1) {
System.out.println("Hello, JVM!");
}
}
}
第2次执行时,正则表达式将flag替换为2:
public class Foo {
public Foo() {
}
public static void main(String[] var0) {
byte flag = 2;
if (flag != 0) {
System.out.println("Hello, Java!");
}
if (flag == 1) {
System.out.println("Hello, JVM!");
}
}
}
可以简写为
java -jar /path/to/asmtools.jar jdis Foo.class > Foo.jasm.1
如果不是Java虚拟机和jre有啥区别嘛?
这个地方可以展开说一下吗?c++不可以直接执行,why?c++不是编译成机器码了吗?JAVA像c++那样直接编译成目标机器的机器码为什么不现实?
0 完整的输入记录 n 当前记录的第n个字段,字段间由FS分隔
iconst_1 为 pattern
/iconst_1/ 两个/表示正则表达式的开始结束符号
最后那个1为定值,非0
参考资料如下:
https://blog.csdn.net/xp5xp6/article/details/50531396
http://www.runoob.com/linux/linux-comm-awk.html
http://www.runoob.com/w3cnote/awk-built-in-functions.html
但是把第一个iconst_1替换为iconst_2有什么用呢?有点不理解。
JIT和ART的区别我没太理解,边翻译边执行不是JIT吗?
如果说JIT检测到是热点代码并且进行优化,那么为什么解释执行不直接就用这种优化去解释字节码?
一些比较浅的问题,希望老师能指点一二
我觉得主要是为了避免系统语言(例如C语言、C++等)与平台的强耦合性,不易移植的缺点,从而实现“一次编写,到处运行”的平台无关性。
阅读完后我还有这些疑问,麻烦老师解答一下😃
istore_1;
iload_1;
ifeq L14;
getstatic Field java/lang/System.out:"Ljava/io/PrintStream;";
ldc String "Hello,Java!";
invokevirtual Method java/io/PrintStream.println:"(Ljava/lang/String;)V";
L14: stack_frame_type append;
locals_map int;
iload_1;
iconst_1;
if_icmpne L27;
getstatic Field java/lang/System.out:"Ljava/io/PrintStream;";
ldc String "Hello,JVM!";
invokevirtual Method java/io/PrintStream.println:"(Ljava/lang/String;)V";
L27: stack_frame_type same;
return;
line1:入栈2
line2:栈顶int存入第二个局部变量(第一个存放的是this)
line3:局部变中量表第二个局部变量入栈
line4:判断栈顶是否为零(为2不为0)
line10:局部变中量表第二个局部变量入栈
line11:入栈1
line12:比较栈顶是否相等(1和2自然是不等的)
hello java 和hello jvm都可以,但是我看到留言中有位高手的详解中说第二个不打印,有点郁闷
我这边windows是可以做做作业的,首先把.gz里的.zip打开然后进入asmtool6.0/lib中,把asmtools.jar解压到指定位置,然后将作业代码,asmtools的路径对应修改即可。
原理请看评论第一高手
运行时 即时编译 分C1. C2, G. 多种可能
先C1 再 C2
java9有了aot解决启动时间问题
asmtools jasm/jdis
这句话有个疑问:
解释执行的方式运行也是需要编译成机器码的对吧,只不过是逐条编译?
有些性能调优会让把线程栈内存调低一点,这是为什么?只是为了能有更多的线程么?
c++的语法和抽象程度不比Java低,但是在本地跑,感觉这句话不是很准确,逻辑可以调整下
什么时候会将字节码加载到jvm的方法区呢?
另外您说的编译是指什么?当java文件变为class文件的时候不就是已经编译过了吗?这个时候在jvm中存放的不就是class文件了吗
你好,理论上讲,可能超过,那么实际上呢,是什么情况?从统计上来看,实现同样的功能,JAVA程序比c++慢多少?慢一倍?10%?